PYTHON日記 ”Python実践データ加工/可視化100本ノック”をやってみた 4

第2章(ノック21〜40)
第2章は、エクセルファイルの操作です。エクセルVBAで加工することも当然できるのですが、PYTHONでも同様のことができるというわけです。最近エクセルをPYTHONで操作するという本なども出ていますが、エクセルとより親和性が高いVBAではなくあえてPYTHONを使うメリットがよく分かりませんし、そもそもセキュリティポリシーを盾にPYTHON環境をインストールを認めない職場が多いと思うので実用性に疑問符です。ただし、それはエクセルファイルを単体で加工・活用する場合であって、エクセルで作成されたデータを他のフォーマットのデータと統合して分析・加工する処理をオートメーション化するのであればメリットが出てきます。
それにしても、エクセルは、セルサイズを細分化して方眼紙代わりに使ってみたり、紙のイメージに近づけるためにセルを結合してみたり、データとして活用するには適していない使われ方をしていますね。総務省が2020年にまとめた「統計表における機械判読可能なデータの表記方法の統一ルールの策定」が普及していくといいのにと思いますが、多分無理でしょう。

総務省|報道資料|統計表における機械判読可能なデータの表記方法の統一ルールの策定
総務省では、各府省が政府統計の総合窓口(e-Stat)に掲載する統計表における機械判読可能なデータの表記方法の統一ルールを策定いたしましたので、お知らせいたします。
結局データ活用の際にエクセルファイルを作った人(組織)の癖を把握して、プログラムで加工・修正するといった前処理は今後も欠かせないと思います。別に総務省にケチをつける気はありませんが、メールアドレスの「@」を「_atmark_」に変えて、スパムメール対策になると本当に思っているのでしょうか。
いろいろ能書きをたれましたが、やってみるとピボットテーブルを作れたり、ブック内の複数のシートを指定できるなど、結構器用なことができることがわかり、なるほどと感心しました。
この章での私が学んだ主な内容、感想は以下のとおりです。後半は作成したデータを可視化するメソッドが続いていますが、実際に使うときに復習することにし、この要約では省きました
- エクセルデータを読み込む(不必要な行はスキップする)
- (Pandasをpdとして読み込んで)pd.read_excel(`ファイル名`, skiprows = x, header = None) skiprowsは最初のx行を飛ばしたい時に指定。最初の行をヘッダーとして扱わない場合はNone
- カラムデータの整備
- セル結合で空白(NaN)となっているセルにデータを補完する。
- 補完は、for文でループさせて、空白となっているセルに左隣のセルのデータを代入(fillna)する。
- 全シート(同じブック内に対象データがあるとき)を読み込み結合する。
- pd.ExcelFile(‘Filename’)でエクセルファイルの情報(含まれるシート名など)を取得する。
- 全てのシートをループさせて、データを取得(parse)し、リストに加える(append)。
- データフレームとして使えるよう、リストにpandasのデータフレームを追加する(concat)。
- 必要に応じてデータ値を再計算した値に変更する。
- 必要なカラムだけに絞り込む。
- 基本的には元データはそのまま保存しておく方がよい。
- 縦持ちデータを作成する。
- 縦持ちデータとは下図のようなもの。
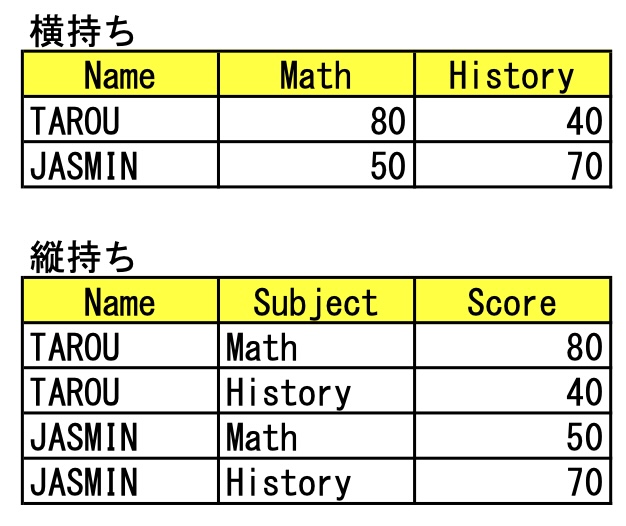
- pandasのmeltでキー列を指定して作成する。
- ExcelではPowerQueryを使えば縦持ちデータを作成できるらしいが、MacのOffice365には該当のメニューが表示されない……。
- 縦持ちデータとは下図のようなもの。
